Le code dans cet article a été écrit avec Code::Blocks.
Vous pouvez trouver
ici un guide pour installer ce logiciel.
Introduction à la méthode
Le run-length encoding (RLE) est probablement la méthode de compression la plus simple.
Elle était utilisée dans de vieux formats d'image comme Truevision Targa, Windows BMP, PCX et IFF-ILBM quand les
images palettisées de de 32 couleur ou moins étaient courantes. Et aussi dans certains format spécifiques pour les
jeux.
Elle fonctionne en cherchant des "chaînes" qui contiennent seulement un élément répété plusieurs fois.
On va appeler ces chaînes des "runs".
Alors on va expliquer ça en utilisant des chaînes de caractères ASCII.
Prenons la chaîne "AAAAAEEEFFFFAAAHHHHJJJJJHHHH".
Elle contient 28 lettres. Donc 28 octets si on utilise le codage ASCII standard.
Mais si vous deviez la décrire à quelqu'un au téléphone, vous n'épelleriez pas chaque lettre.
Vous diriez plutôt "Il y a "cinq" "A", "trois" "E", "quatre" "F", ..."
C'est l'idée de base du run-length encoding.
Chaque run comme "AAAAA" est "encodé" sous une forme plus compacte comme (5) A.
Alors au lieu d'épeler 5 lettres, on utilise un nombre et une lettre.
En utilisant cette méthode, notre chaîne ressemblera à ça:
(5)A (3)E (4)F (3)A (4)H (5)J (4)H
Maintenant, si on considère qu'on utilise 1 octet pour les nombres, ce codage utilise seulement 14 octets pour
décrire notre chaîne de 28 lettres.
Alors écrivons un simple programme C pour encoder cette chaîne.
Il va commencer de manière classique en incluant quelques en-têtes et en définissant un type de données pour rendre
le code un peu plus lisible:
#include <stdio.h>
#include "main.h"
#include <string.h>
typedef unsigned char u8;
int main(int argc, char* argv[])
{
Voici notre chaîne stockée dans un tableau. Et on stocke sa longueur dans une variable:
u8 input[] = "AAAAAEEEFFFFAAAHHHHJJJJJHHHH";
int inputSize = strlen((char*)input);
On va stocker le résultat de l'encodage dans une autre tableau. Dans le pire des cas, il utilisera 2 fois plus
d'octets.
u8 output[inputSize * 2];
int outputSize = 0;
Ces 2 lignes vont afficher la chaîne de départ à l'écran:
printf("input: %s\n", input);
printf("input size: %d\n", inputSize);
On va traiter un par un les caractères de la chaine en entrée.
Ces 2 variables vont stocker l'index du premier caractère du run qu'on est en train de traiter, et l'index du
caractère courant.
int runStart = 0;
int currentByte = 1;
Ensuite, on démarre la boucle sur chaque caractère, et on calcule la longueur du run courant.
while (true)
{
int runLength = currentByte - runStart;
Si l'octet courant est différent du premier du run.
Ou qu'on atteint la fin ce la chaîne d'entrée.
Ou que la longueur du run courant est 255...
if (input[currentByte] != input[runStart] ||
currentByte == inputSize ||
runLength == 255)
{
... alors on écrit le run dans le tableau de sortie, et on en démarre un nouveau.
output[outputSize++] = runLength;
output[outputSize++] = input[runStart];
runStart = currentByte;
}
Si on atteint la fin de la chaine d'entrée, on sort de la boucle.
if (currentByte == inputSize)
break;
Sinon, on incrémente l'index de l'octet courant, et on reboucle au début
currentByte++;
}
Finalement on affiche le résultat:
printf("output: ");
for (int i = 0; i < outputSize; i += 2)
{
printf("(%d)", output[i]);
printf("%c ", output[i + 1]);
}
printf("\n");
printf("output size: %d\n", outputSize);
return 0;
}
Télécharger le code source
Télécharger l'exécutable pour Windows
Comme on s'y attendait, le résultat de ce programme est:
input: AAAAAEEEFFFFAAAHHHHJJJJJHHHH
input size: 28
output: (5)A (3)E (4)F (3)A (4)H (5)J (4)H
output size: 14
Maintenant, cet exemple marche, mais qu'est-ce qu'il se passe si on essaye avec une chaine comme "AEFAHJHABGHOZ" où
il n'y a pas de répétition ?
input: AEFAHJHABGHOZ
input size: 13
output: (1)A (1)E (1)F (1)A (1)H (1)J (1)H (1)A (1)B (1)G (1)H (1)O (1)Z
output size: 26
Télécharger le code source
Télécharger l'exécutable pour Windows
La sortie est 2 fois plus longue que l'entrée. Ca n'est pas une compression très efficace...
Codes, compteurs, runs et chaînes
Le problème est que lorsqu'il n'y a pas de répétition, on veut stocker les caractères tels quels, sans ajouter de
données superflues.
Mais quand on trouve une répétition, on veut utiliser l'encodage qu'on a vu auparavant.
Pour expliquer ça, prenons cette chaîne: "ABCDAAAABBCDDDDEEEEE".
Dans les 4 premiers caractères "ABCD" il n'y a pas de répétition, alors on veut un code qui dise "écrit les 4
caractères ABCD".
Les 4 caractères suivants sont la lettre "A" répétée 4 fois, alors on veut un code qui dise "écrit 4 A".
Alors à quoi vont ressembler ces 2 types de codes ?
On a déjà vu le code pour un "run", c'était un "compteur" suivi de la lettre qu'on voulait répéter.
On va maintenant définir le même type de code pour une "chaîne". On va avoir un "compteur" suivi des lettres qui
seront recopiées telles quelles.
Mais comment faire la différence entre le code d'un "run" et le code d'une chaîne ?
Eh bien, auparavant on a utilisé un octet pour le "compteur". Donc le nombre de répétitions pouvait aller de 0 à
255.
Maintenant disons que pour les chaînes on va utiliser les valeurs de 0 à 127, et pour les runs on utilisera les
valeurs 128 à 255.
On aura juste besoin de soustraire 128 du compteur du run pour obtenir le nombre de répétition du caractère.
Donc notre chaîne va ressembler à ça:
(4)ABCD (132)A ...
Maintenant pour coder ça, notre boucle de traitement va contenir 2 état.
On va d'abord considérer qu'on est dans l'état "chaîne" et traiter les caractère un par un, et si on voit que le
même caractère est répété un certain nombre de fois on basculera dans l'état "run".
L'état "run" est fondamentalement là même boucle que l'on a expliqué dans le chapitre précédent. On va traiter la
chaîne jusqu'à ce qu'on trouve un caractère qui ne correspond pas à notre "run".
Pour le nombre minimum de répétition qui va déclencher le basculement entre les états, on va prendre 3.
Maintenant programmons ça.
On va commencer par définir quelques constantes qui nous donneront les valeurs minimum et maximum des compteurs
pour chaque code.
#include <stdio.h>
#include "main.h"
#include <string.h>
typedef unsigned char u8;
#define MIN_RUN 3
#define MAX_RUN 127
#define MIN_STRING 1
#define MAX_STRING 127
J'ai mis la routine de compression dans une fonction séparée pour plus de clarté:
void compress(u8* input, int& inputSize, u8* output, int& outputSize)
{
Comme avant, on va utiliser un index pour le début du run courant, et pour le caractère courant.
Mais on va aussi avoir besoin d'un index pour le début de la chaîne courante.
La variable "isInRun" va nous dire si on est dans l'état "chaîne" ou dans l'état "run". Au départ elle est mise à
false parce qu'on considère qu'on est dans une chaîne.
int stringStart = 0;
int runStart = 0;
int currentByte = 1;
bool isInRun = false;
On commence la boucle de traitement.
while (true)
{
Si on est dans l'état "chaîne"...
if (isInRun == false)
{
// string mode
Au départ on va mettre à jour l'index runStart si on a trouvé un caractère qui n'est pas le même que le run courant.
if (input[currentByte] != input[runStart])
runStart = currentByte;
Ensuite j'ai essayé d'écrire le code de la même manière que celui qu'on a vu dans le premier chapitre.
Donc on calcule la longueur de la "chaîne" courante et celle du run courant.
int stringLength = runStart - stringStart;
int runLength = currentByte + 1 - runStart;
Puis on teste les conditions pour terminer la chaîne:
Soit on a atteint la fin de l'entrée.
Ou on a trouvé un "run" qui est assez long pour qu'on bascule dans l'état "run".
Ou le compteur de longueur de la "chaîne" a atteint sa valeur maximale.
if (currentByte == inputSize ||
runLength == MIN_RUN ||
stringLength == MAX_STRING)
{
Si une de ces conditions est remplie on écrit la "chaîne" dans la sortie.
// emit string
if (stringLength >= MIN_STRING)
{
output[outputSize++] = stringLength;
for (int i = 0; i < stringLength; i++)
output[outputSize++] = input[stringStart++];
}
Puis, seulement si la condition de longueur minimale de run est remplie, on bascule dans l'état "run".
// go to run mode
if (runLength == MIN_RUN)
isInRun = true;
}
}
L'état "run" est pratiquement identique au code qu'on a vu dans le premier chapitre. La principale différence est
qu'on ajoute 128 au compteur quand on écrit le run, et qu'on rebascule dans l'état "chaîne".
else
{
// run mode
stringStart = currentByte;
int runLength = currentByte - runStart;
if (input[currentByte] != input[runStart] ||
currentByte == inputSize ||
runLength == MAX_RUN)
{
// emit run
output[outputSize++] = 128 + runLength;
output[outputSize++] = input[runStart];
runStart = currentByte;
// go to string mode
isInRun = false;
}
}
Enfin la fin de la boucle est la même que dans le premier chapitre.
On sort de la boucle si on a atteint la fin de l'entrée, et on incrémente l'index du caractère courant.
Et on a fini la fonction de compression.
if (currentByte == inputSize)
break;
currentByte++;
}
}
La fonction principale ne fait qu'entrer la chaîne de départ dans la fonction de compression et affiche le
résultat, en prenant en compte les 2 types de "codes" qu'on peut avoir.
int main(int argc, char* argv[])
{
u8 input[] = "ABCDAAAABBCDDDDEEEEE";
int inputSize = strlen((char*)input);
u8 output[inputSize * 2];
int outputSize = 0;
printf("input: %s\n", input);
printf("input size: %d\n", inputSize);
compress(input, inputSize, output, outputSize);
printf("output: ");
int i = 0;
while (i != outputSize)
{
printf("(%d)", output[i]);
if (output[i] < 128)
{
int length = output[i++];
for (int j = 0; j < length; j++)
printf("%c", output[i++]);
}
else
{
i++;
printf("%c", output[i++]);
}
printf(" ");
}
printf("\n");
printf("output size: %d\n", outputSize);
return 0;
}
Télécharger le code source
Télécharger l'exécutable pour Windows
La sortie de ce programme nous montre un vrai encodage RLE.
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (4)ABCD (132)A (3)BBC (132)D (133)E
output size: 15
Maintenant regardons les constantes qu'on a définies au début du programme.
#define MIN_RUN 3
#define MAX_RUN 127
#define MIN_STRING 1
#define MAX_STRING 127
La longueur minimale d'un run est 3. Donc le compteur ne sera jamais 128, 129 ou 130.
On ne verra jamais une chaîne de longueur 0 non plus.
Alors on peut utiliser ces faits pour étendre les valeurs maximum que les compteurs peuvent prendre.
Disons que pour un run, quand on a un compteur de 128, on aura 3 répétition.
On doit simplement soustraire MIN_RUN du compteur quand on écrit le run.
// emit run
output[outputSize++] = 128 + runLength - MIN_RUN;
De même on soustrait MIN_STRING au compteur d'une "chaîne".
output[outputSize++] = stringLength - MIN_STRING;
Et maintenant les compteurs peuvent prendre des valeurs maximales plus grandes
#define MIN_RUN 3
#define MAX_RUN (127 + MIN_RUN)
#define MIN_STRING 1
#define MAX_STRING (127 + MIN_STRING)
Télécharger le code source
Télécharger l'exécutable pour Windows
Il a aussi fallu faire une petite modification quand on affiche le résultat à l'écran mais ce n'est pas la partie
la plus importante.
Voici maintenant la sortie de ce programme:
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (3)ABCD (129)A (2)BBC (129)D (130)E
output size: 15
Remarquez que le premier code (3)ABCD veut dire qu'on va copier (3 + 1) caractères.
Et le deuxième code (129)A veut dire qu'on va répéter A 4 fois.
Maintenant qu'on a une fonction de compression écrivons celle de décompression.
Celle-ci est facile. En fait elle ressemble beaucoup au code qu'on a utilisé pour afficher la sortie compressée.
On va commencer par initialiser 2 variables.
"i" est l'index courant dans la chaîne d'entrée, et "outputSize" est le nombre d'octets qu'on à sortis pour
l'instant.
void uncompress(u8* input, int& inputSize, u8* output, int& outputSize)
{
int i = 0;
outputSize = 0;
Ensuite, on va boucler jusqu'à ce qu'on atteigne la fin de l'entrée:
while (i != inputSize)
{
Le premier octet qu'on "lit" est le compteur. S'il est inférieur à 128, on a une chaîne, et on l'écrit dans la
sortie.
if (input[i] < 128)
{
int length = input[i++] + MIN_STRING;
for (int j = 0; j < length; j++)
output[outputSize++] = input[i++];
}
Si le compteur était supérieur ou égal à 128, on a un run et on l'écrit.
Puis on reboucle au début.
else
{
int length = input[i++] - 128 + MIN_RUN;
for (int j = 0; j < length; j++)
output[outputSize++] = input[i];
i++;
}
}
}
Alors on va simplement appeler cette fonction après qu'on a compressé notre chaîne et voir ce qu'on obtient:
uncompress(output, outputSize, input, inputSize);
printf("uncomp: %s\n", input);
printf("uncompSize: %d\n", inputSize);
Télécharger le code source
Télécharger l'exécutable pour Windows
Et voici le résultat de ce programme. Comme on s'y attendait, on retrouve notre chaîne de départ.
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (3)ABCD (129)A (2)BBC (129)D (130)E
output size: 15
uncomp: ABCDAAAABBCDDDDEEEEE
uncompSize: 20
Maintenant que nos fonctions marchent sur de petites chaînes, on va les tester sur de plus grandes données.
La façon la plus facile de faire ça est de compresser un fichier.
Alors je vais commencer par écrire quelques fonctions utilitaires pour les fichiers.
La fonction fileGetSize va retourner la taille d'un fichier:
int fileGetSize(char* fileName)
{
int fileSize;
FILE* f = fopen(fileName, "rb");
fseek(f, 0, SEEK_END);
fileSize = ftell(f);
fclose(f);
return fileSize;
}
La fonction fileLoad alloue de la mémoire et charge un fichier dedans.
int fileLoad(char* fileName, u8** mem)
{
int fileSize = fileGetSize(fileName);
*mem = (u8*)malloc(fileSize);
FILE* f = fopen(fileName, "rb");
fread(*mem, 1, fileSize, f);
fclose(f);
return fileSize;
}
La fonction fileSave sera utilisée pour sauvegarder soit un fichier compressé soit un fichier décompressé.
La seule différence entre les deux est que dans le cas d'un fichier compressé, on ajoute un int au début qui
contient la taille des données décompressées. C'est le paramètre originalSize. Il est seulement ajouté au fichier
s'il n'est pas égal à 0.
void fileSave(char* fileName, u8* mem, int fileSize, int originalSize)
{
FILE* f = fopen(fileName, "wb");
if (originalSize != 0)
fwrite(&originalSize, sizeof(int), 1, f);
fwrite(mem, 1, fileSize, f);
fclose(f);
}
Maintenant en utilisant ces fonctions utilitaires on peut écrire les fonctions qui vont compresser ou décompresser
un fichier.
D'abord la fonction fileCompress.
- Elle charge un fichier
- alloue de la mémoire pour les données compressées
- appelle la fonction de compression
- sauvegarde le résultat dans un autre fichier
- puis libère la mémoire temporaire qu'elle a alloué
void fileCompress(char* srcName, char* destName)
{
u8* input;
int inputSize;
u8* output;
int outputSize = 0;
inputSize = fileLoad(srcName, &input);
printf("original size: %d\n", inputSize);
output = (u8*)malloc(inputSize * 2);
compress(input, inputSize, output, outputSize);
fileSave(destName, output, outputSize, inputSize);
printf("compressed size: %d\n", outputSize);
free(input);
free(output);
}
Ensuite la fonction fileUncompress.
- Elle charge un fichier
- Comme ce fichier a été sauvé par la fonction fileSave, elle lit le premier int qui donne la taille des
données décompressées
- elle alloue de la mémoire pour les données décompressées
- appelle la fonction de décompression
- sauvegarde le résultat dans un autre fichier
- puis libère la mémoire temporaire qu'elle a alloué
void fileUncompress(char* srcName, char* destName)
{
u8* input;
int inputSize;
u8* output;
int outputSize = 0;
inputSize = fileLoad(srcName, &input);
outputSize = *((int*)input);
output = (u8*)malloc(outputSize);
inputSize -= sizeof(int);
uncompress(input + sizeof(int), inputSize, output, outputSize);
fileSave(destName, output, outputSize, 0);
printf("uncompressed size: %d\n", outputSize);
free(input);
free(output);
}
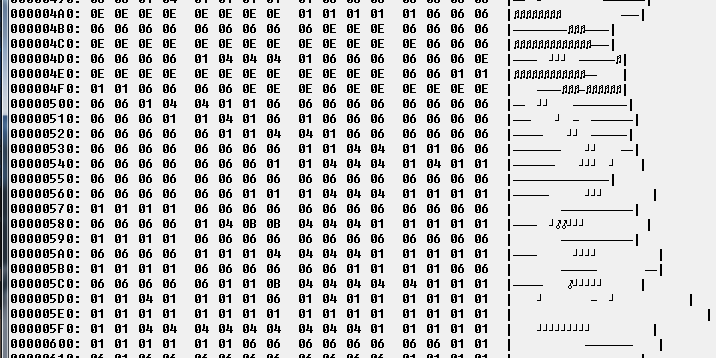
Pour tester ces fonctions, j'ai choisi de compresser une image Targa non compressée de 16 couleurs.
Comme vous pouvez le voir, il y a de grandes zones de pixels contigus qui ont la même couleur.
J'écrirai un article sur le format Targa plus tard, mais ici je vais brièvement expliquer ce qu'il contient.
Il commence avec un petit entête qui donne des informations sur l'image comme sa taille en pixels.
Puis une autre petite zone contient la palette de couleurs.
Et la plus grosse partie du fichier est les données de l'image qui contiennent un octet par pixel.
Chacun de ces octets a une valeur entre 0 et 15 parce que c'est une image 16 couleurs.
Voici une partie de ce fichier dans un éditeur hexa:
Pour compresser ce fichier, la fonction principale va appeler les fonctions de compression qu'on vient d'écrire:
int main(int argc, char* argv[])
{
fileCompress("image.tga", "comp.rle");
fileUncompress("comp.rle", "uncomp.tga");
return 0;
}
Télécharger le code source
Télécharger l'exécutable pour Windows
Et voilà la sortie de ce programme.
Si vous ouvrez le fichier décompressé, vous verrez que c'est le même que celui d'origine.
original size: 459986
compressed size: 170209
uncompressed size: 459986
Ce n'est pas la seule façon de faire un run length encoding.
Tout au long de cet article on a fait plusieurs choix arbitraires et vous pouvez obtenir un autre codage en
modifiant ces choix.
D'abord on a fixé la taille des "compteurs" sur 1 octet. Plusieurs méthodes de compression écrivent les données bit
par bit plutôt qu'octet par octet. Alors si on avait écrit des fonctions pour manipuler des champs de bits on
aurait pu choisir d'utiliser un "compteur" de 6 bits par exemple.
Le gain en bits peut être contrebalancé par la longueur maximum des runs. Ca dépend des données que vous voulez
compresser.
Dans nos "codes" les données après le "compteur" sont aussi considérées comme des octets. Mais dans le cas de notre
image Targa, si on oublie l'entête et la palette, chaque donnée de pixel contient une valeur entre 0 et 15. Ca peut
tenir sur 4 bit au lieu des 8 bits d'un octet complet.
Dans certains cas c'est mieux de considérer que les données sont plus grandes qu'un octet. Par exemple dans le
format Targa, le RLE ne fonctionne pas sur des octets mais sur des pixels. Et comme ce format peut gérer des images
true color, les données peuvent avoir une largeur de 8, 16, 24, ou 32 bits.
Un "run" encodé dans ce format pourrait ressembler à ça "(8)0xAA 0xBB 0xCC" qui veut dire répéter 8 fois le même
pixel, 0xAA, 0xBB et 0xCC étant les valeurs de rouge, vert et bleu de ce pixel.
On a aussi choisi d'utiliser la valeur 128 dans le "compteur" pour distinguer les "chaînes" des "runs". Ca veut
dire que c'est le bit de poids le plus fort du "compteur".
On aurait pu choisir d'utiliser le bit de poids le plus faible par exemple. Ca signifierait que si le compteur est
pair on aurait un "run" et s'il est impair on aurait une "chaîne", puis on aurait à décaler cette valeur vers la
droite pour obtenir le nombre d'octets à copier ou à répéter.
On aurait aussi pu choisir de changer l'équilibre entre les "runs" et les "chaînes", si on dit que les 2 bits de
poids les plus forts d'un "compteur" codent un "run" s'ils sont tous les deux à 1, tandis que les autres combinaisons
00, 01 et 10 codent une "chaîne".
Les encodages RLE les plus avancés utilisent plusieurs codes, pas seulement un "run" et une "chaîne".
J'ai du faire de la rétro-ingénierie sur un ancien jeu qui utilisait des sprites encodés en RLE.
Comme c'était des sprites, en plus de leurs pixels colorés, ils étaient entourés de pixels transparents.
Et chaque sprite pouvait avoir une ombre qui était des pixels noirs avec un alpha à 50% qui se mélangeait avec le
décor de fond.
Donc cet encodage utilisait différents "codes":
- Un code "chaîne" pour les pixels colorés
- A code "run" pour les pixels colorés
- A code "run" pour les pixels transparents
- Et un autre code "run" pour les ombres
Ces codes et la longueur des runs qu'ils pouvaient définir avaient probablement été réglés finement pour fournir la
meilleure compression sur une grande quantité de sprites.