The code in this article was written using Code::Blocks.
You can read
here a guide to install this sofware.
Introduction to the method
The run-length encoding (RLE) is probably the simplest method of compression.
It is used in some old image formats like Truevision Targa, Windows BMP, PCX and IFF-ILBM when palette-based
images of 32 colors or less were common. And in some game specific formats.
It works by looking for "strings" that contains only one element repeated many times.
Those strings are called "runs".
Now we will explain that using text strings of ascii characters.
Let's take the string "AAAAAEEEFFFFAAAHHHHJJJJJHHHH".
It contains 28 letters. So 28 bytes if we use the standard ASCII encoding.
But if you had to describe it to somebody on the phone you would not spell every letter.
You would rather say "There is "five" "A", "three" "E", "four" "F", ..."
That's the core idea of the run-length encoding.
Each run like "AAAAA" is "encoded" in a more compact form as (5) A.
So instead of spelling 5 letters, we use a number and a letter.
Using this method, our string would look like this:
(5)A (3)E (4)F (3)A (4)H (5)J (4)H
Now if we assume that we use 1 byte for the numbers, this encoding only use 14 bytes to describe our 28 letters
string.
So let's write a simple C program to encode this string.
It will start in a classical way by including a few headers and defining a data type to make the code a bit more
readable:
#include <stdio.h>
#include "main.h"
#include <string.h>
typedef unsigned char u8;
int main(int argc, char* argv[])
{
This is our string stored in an array. And we store its length in a variable:
u8 input[] = "AAAAAEEEFFFFAAAHHHHJJJJJHHHH";
int inputSize = strlen((char*)input);
We will store the encoded result in another array. In the worst case it will use 2 times more bytes.
u8 output[inputSize * 2];
int outputSize = 0;
These 2 lines will display the input string on the screen:
printf("input: %s\n", input);
printf("input size: %d\n", inputSize);
We will parse the input string characters one by one.
These 2 variables will store the index of the first character in the run we are processing, and the index of the
current character.
int runStart = 0;
int currentByte = 1;
Then we start the loop over each characters, and whe calculate the length of the current run.
while (true)
{
int runLength = currentByte - runStart;
If the current byte is different from the first of the run.
Or if we hit the end of the input string.
Or if the length of the current run is 255...
if (input[currentByte] != input[runStart] ||
currentByte == inputSize ||
runLength == 255)
{
... Then we write the run to the output array, and we start a new one.
output[outputSize++] = runLength;
output[outputSize++] = input[runStart];
runStart = currentByte;
}
If we hit the end of the input string, we exit the loop.
if (currentByte == inputSize)
break;
Else we increment the current byte index and we loop back
currentByte++;
}
Finally, we print the result:
printf("output: ");
for (int i = 0; i < outputSize; i += 2)
{
printf("(%d)", output[i]);
printf("%c ", output[i + 1]);
}
printf("\n");
printf("output size: %d\n", outputSize);
return 0;
}
Download source code
Download executable for Windows
As expected, the result of this program is:
input: AAAAAEEEFFFFAAAHHHHJJJJJHHHH
input size: 28
output: (5)A (3)E (4)F (3)A (4)H (5)J (4)H
output size: 14
Now this example works, but what happens if we try with a string like "AEFAHJHABGHOZ" where there is no repetition?
input: AEFAHJHABGHOZ
input size: 13
output: (1)A (1)E (1)F (1)A (1)H (1)J (1)H (1)A (1)B (1)G (1)H (1)O (1)Z
output size: 26
Download source code
Download executable for Windows
The output is twice as long as the input. This is not a very efficient compression...
Codes, counts, runs and strings
The problem is that when there is no repetition, we want to store the characters as is, without adding useless
datas.
But when we find a repetition we want to use the encoding we saw above.
To explain that, let's take this string: "ABCDAAAABBCDDDDEEEEE".
In the first 4 characters "ABCD" there is no repetition, so we want a code that says "write the 4 characters ABCD".
The 4 following characters is the letter "A" repeated 4 times, so we want a code that says "write 4 A".
Now what will theses 2 types of codes look like ?
We already saw the code for a "run" it was a "count" followed by the letter we wanted to repeat.
We will now define the same type of code for a "string". We will have a "count" followed by the letters that will
be copied "as-is".
But how to tell the difference between a "run" code and a "string" code ?
Well, previously we used one byte for the "count". So the number of repetitions could go from 0 to 255.
Now let's say that for the strings we will use the values 0 to 127, and for the runs we will use values 128 to 255.
We will only have to subtract 128 from the run counter to get the number of characters to repeat.
So our string will look like:
(4)ABCD (132)A ...
Now, to code that our parsing loop will contain 2 states.
We will first assume that we are in the "string" state and parse the characters one by one, and if we see that the
same character is repeated a given amount of time we will switch to the "run" state.
The "run" state is basically the same loop we explaind in the previous chapter. We will parse the string until we
find a character that does not match our run.
For the minimum amount of repetitions that will trigger the switch between the states, we will take 3.
Now let's code that.
We will start by defining a few constants giving the minimum and maximum values of the counters for each code.
#include <stdio.h>
#include "main.h"
#include <string.h>
typedef unsigned char u8;
#define MIN_RUN 3
#define MAX_RUN 127
#define MIN_STRING 1
#define MAX_STRING 127
I have put the compression routine in a seperate function for clarity:
void compress(u8* input, int& inputSize, u8* output, int& outputSize)
{
As before, we will use an index for the start of the current run and for the current character.
But we will also need an index for the start of the current string.
The "isInRun" variable will tell us if we are in the "string" state, or the "run" state. At the beginning it is
set to false because we assume we are in a string.
int stringStart = 0;
int runStart = 0;
int currentByte = 1;
bool isInRun = false;
We begin the parsing loop.
while (true)
{
If we are in the "string" state...
if (isInRun == false)
{
// string mode
At first we will update the runStart index if we found a character that is not the same of the current run.
if (input[currentByte] != input[runStart])
runStart = currentByte;
Then I tried to write this code in the same way as the one we saw in the first chapter.
So we compute the length of the current "string" and the length of the current run.
int stringLength = runStart - stringStart;
int runLength = currentByte + 1 - runStart;
Then we check the conditions to end the string:
Either we reached the end of the input.
Or we found a "run" that is long enough so that we can switch to the "run" state.
Or the "string" length counter has reached its maximum value.
if (currentByte == inputSize ||
runLength == MIN_RUN ||
stringLength == MAX_STRING)
{
If one of these conditions is fulfilled, we output the "string".
// emit string
if (stringLength >= MIN_STRING)
{
output[outputSize++] = stringLength;
for (int i = 0; i < stringLength; i++)
output[outputSize++] = input[stringStart++];
}
Then, only if the minimal run length condition was true, we switch to the "run" state.
// go to run mode
if (runLength == MIN_RUN)
isInRun = true;
}
}
The "run" state is nearly identical to the code in the first chapter. The main difference is that we add 128 to the
counter when we output the "run", and we switch back to the "string" state.
else
{
// run mode
stringStart = currentByte;
int runLength = currentByte - runStart;
if (input[currentByte] != input[runStart] ||
currentByte == inputSize ||
runLength == MAX_RUN)
{
// emit run
output[outputSize++] = 128 + runLength;
output[outputSize++] = input[runStart];
runStart = currentByte;
// go to string mode
isInRun = false;
}
}
Then the end of the loop is the same as what we saw in the first chapter.
We break out of the loop if we reached the end of the input, and we increment the current character index.
And we're done with the compression function.
if (currentByte == inputSize)
break;
currentByte++;
}
}
The main function only feeds the input string to the compression function and prints out the result, taking into
account the 2 types of "codes" we can get.
int main(int argc, char* argv[])
{
u8 input[] = "ABCDAAAABBCDDDDEEEEE";
int inputSize = strlen((char*)input);
u8 output[inputSize * 2];
int outputSize = 0;
printf("input: %s\n", input);
printf("input size: %d\n", inputSize);
compress(input, inputSize, output, outputSize);
printf("output: ");
int i = 0;
while (i != outputSize)
{
printf("(%d)", output[i]);
if (output[i] < 128)
{
int length = output[i++];
for (int j = 0; j < length; j++)
printf("%c", output[i++]);
}
else
{
i++;
printf("%c", output[i++]);
}
printf(" ");
}
printf("\n");
printf("output size: %d\n", outputSize);
return 0;
}
Download source code
Download executable for Windows
The result of this code shows us a real RLE encoding.
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (4)ABCD (132)A (3)BBC (132)D (133)E
output size: 15
Now take a look at the constants we defined at the beginning of the program.
#define MIN_RUN 3
#define MAX_RUN 127
#define MIN_STRING 1
#define MAX_STRING 127
The minimal length of a run is 3. So the "count" will never be 128, 129 or 130.
We'll never see a "string" of length 0 too.
So we can use this fact to expand the maximum value the counts can take.
Let's say for a run that when we have a count of 128, we will have 3 repetitions.
We simpy have to subtract MIN_RUN from the count when we output the run.
// emit run
output[outputSize++] = 128 + runLength - MIN_RUN;
Similarly we will substract MIN_STRING from the "string" count.
output[outputSize++] = stringLength - MIN_STRING;
And now the counts can have greater maximum values
#define MIN_RUN 3
#define MAX_RUN (127 + MIN_RUN)
#define MIN_STRING 1
#define MAX_STRING (127 + MIN_STRING)
Download source code
Download executable for Windows
We also had to make a small modification when we print out the result on the screen, but that's not the most
important part.
Now this is the output of this program:
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (3)ABCD (129)A (2)BBC (129)D (130)E
output size: 15
Notice the first code (3)ABCD means that we will copy (3 + 1) characters.
And the second code (129)A means that we will repeat "A" 4 times.
Now that we have a compression function let's write the uncompress one.
This one is easy. In fact it looks a lot like the code we used to print the compressed output.
We will start by initializing 2 variables.
"i" is the current index in the input, and outputSize is the number of bytes we have output so far.
void uncompress(u8* input, int& inputSize, u8* output, int& outputSize)
{
int i = 0;
outputSize = 0;
Then we will loop until we reach the end of the input:
while (i != inputSize)
{
The first byte we "read" is the counter. If it is less than 128, we have a string and we output it.
if (input[i] < 128)
{
int length = input[i++] + MIN_STRING;
for (int j = 0; j < length; j++)
output[outputSize++] = input[i++];
}
If the counter was greater or equal to 128, we have a run and we output it.
Then we loop back.
else
{
int length = input[i++] - 128 + MIN_RUN;
for (int j = 0; j < length; j++)
output[outputSize++] = input[i];
i++;
}
}
}
So we will simply call this function after we compressed our string and see what we get:
uncompress(output, outputSize, input, inputSize);
printf("uncomp: %s\n", input);
printf("uncompSize: %d\n", inputSize);
Download source code
Download executable for Windows
And here is the result of this program. As expected we find our starting string.
input: ABCDAAAABBCDDDDEEEEE
input size: 20
output: (3)ABCD (129)A (2)BBC (129)D (130)E
output size: 15
uncomp: ABCDAAAABBCDDDDEEEEE
uncompSize: 20
Now that our functions works on small strings we will test them on larger datas.
The easiest way to do that is to compress a file.
So I will begin by writing a few file utility functions.
The fileGetSize will return the size of a file:
int fileGetSize(char* fileName)
{
int fileSize;
FILE* f = fopen(fileName, "rb");
fseek(f, 0, SEEK_END);
fileSize = ftell(f);
fclose(f);
return fileSize;
}
The fileLoad function allocates memory and loads the file into it.
int fileLoad(char* fileName, u8** mem)
{
int fileSize = fileGetSize(fileName);
*mem = (u8*)malloc(fileSize);
FILE* f = fopen(fileName, "rb");
fread(*mem, 1, fileSize, f);
fclose(f);
return fileSize;
}
The fileSave function will be used to save both a compressed or an uncompressed file.
The only difference between the two is that in the case of a compressed file, we add an int at the beginning that
contains the size of the uncompressed data. It's the originalSize parameter. It is only added to the file if it is
not equal to 0.
void fileSave(char* fileName, u8* mem, int fileSize, int originalSize)
{
FILE* f = fopen(fileName, "wb");
if (originalSize != 0)
fwrite(&originalSize, sizeof(int), 1, f);
fwrite(mem, 1, fileSize, f);
fclose(f);
}
Now using these utility functions we can write the functions that will compress or uncompress a file.
First, the fileCompress function.
- It loads a file
- allocates memory for the compressed data
- calls the compression function
- saves the result to another file
- then frees up the temporary memory it allocated
void fileCompress(char* srcName, char* destName)
{
u8* input;
int inputSize;
u8* output;
int outputSize = 0;
inputSize = fileLoad(srcName, &input);
printf("original size: %d\n", inputSize);
output = (u8*)malloc(inputSize * 2);
compress(input, inputSize, output, outputSize);
fileSave(destName, output, outputSize, inputSize);
printf("compressed size: %d\n", outputSize);
free(input);
free(output);
}
Then the fileUncompress function.
- It loads a file
- As this file was saved by the fileSave function, it reads the first int that gives the size of the
uncompressed data
- it allocates memory for the uncompressed data
- calls the uncompression function
- saves the result to another file
- then frees up the temporary memory it allocated
void fileUncompress(char* srcName, char* destName)
{
u8* input;
int inputSize;
u8* output;
int outputSize = 0;
inputSize = fileLoad(srcName, &input);
outputSize = *((int*)input);
output = (u8*)malloc(outputSize);
inputSize -= sizeof(int);
uncompress(input + sizeof(int), inputSize, output, outputSize);
fileSave(destName, output, outputSize, 0);
printf("uncompressed size: %d\n", outputSize);
free(input);
free(output);
}
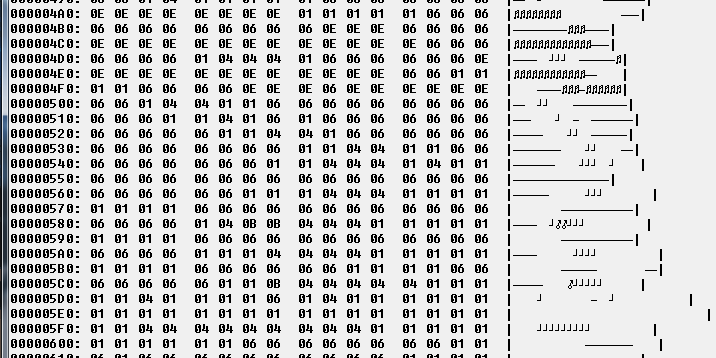
To test these functions I chose to compress a 16 colors uncompressed Targa image.
As you can see there are large areas of contiguous pixels of the same colors.
I will write an article about the Targa format later, but her I will explain briefly what it contains.
It starts with a small header giving informations on the image like its size in pixels.
Then another small area contains the color palette.
And most of the file is the image datas that contains 1 byte per pixel.
Each of these bytes have a value between 0 and 15 because it's a 16 colors image.
Here is a part of the file in an hex editor:
To compress this file, the main function will call the file compression functions we just wrote:
int main(int argc, char* argv[])
{
fileCompress("image.tga", "comp.rle");
fileUncompress("comp.rle", "uncomp.tga");
return 0;
}
Download source code
Download executable for Windows
And here is the output of this program.
If you open the uncompressed file you will see that it is the same as the original.
original size: 459986
compressed size: 170209
uncompressed size: 459986
This is not the only way to do a run length encoding.
Througout this article we made several aribtrary choices and you can get another encoding by modifying these
choices.
First we fixed the "count" length to one byte. Several compression method writes data bit per bit instead of byte
per byte. So if we wrote functions to handle bit field we could have chose to use a 6 bits "count" for example.
The gain in bits could be balanced by the maximum length of runs. That depends on the datas you want to compress.
In our "codes" the datas after the "count" is also considered as bytes. But in the case of our Targa image, if we
forget the header and the palette, each pixel data holds a value between 0 and 15. That can fit in only 4 bits
instead of the 8 bits of a full byte.
In some cases it is better to consider that the datas are larger than a byte. For example in the Targa format the
RLE does not work on bytes but on pixels. And as this format can handle true color images, the datas could be 8,
16, 24, or 32 bits wide.
A "run" encoded in this format could look like this "(8)0xAA 0xBB 0xCC" that means repeat 8 times the same pixel,
0xAA, 0xBB and 0xCC being the red, green and blue values of this pixel.
We also chose to use the value 128 in the "count" to distinguish "strings" from "runs". That means it's the most
significant bit of the "count".
We could have chose to use the least significant bit for example. Meaning that if the count is odd it would be
considered as a "run" and if it is even it would be a "string", then we only would have to shift this value to the
right to get the number of bits to copy or to repeat.
We could also chose to change the balance between "runs" and "strings", if we say that the 2 most significant bits
of a "count" encode a "run" if they are both at 1 while the other combinations 00, 01 and 10 encode a "string".
The most advanced RLE encodings uses several codes, not only one "run" and one string.
I had to reverse engineer an old game that used RLE encoded sprites.
As they were sprites in addition to their colored pixels they were surounded by transparent pixels.
And each sprite could have a shadow that was black pixels with 50% alpha that merged with the background color.
So this encoding used various codes:
- A "string" code for the colored pixels
- A "run" code for the colored pixels
- A "run" code for the transparent pixels
- And another "run" code for the shadows
These codes and the length of the runs they could define were probably fine tuned to provide the best compression
over a lot of sprites.